Episode 2
Les neurones formels
- En 1943, le premier modèle mathématique du neurone est mis au point par McCulloch et Pitts.
Le neurone formel est, comme son nom l'indique, un neurone (on n'avait pas deviné). Seulement, contrairement au neurone biologique, il n'est pas, justement, biologique et pour cause : c'est un neurone mathématique. C'est lui qui est utilisé dans le fonctionnement de l'intelligence artificielle, donc dans le domaine informatique. Nous allons voir ici qu'il a un certain nombre de points communs avec son homologue nerveux (autre que le nom), et bien sûr la façon dont il fonctionne.
I - Je m'appelle Formel... Neurone Formel
Pour fonctionner, le neurone formel a besoin d'informations, appelées entrées, et il renvoie une autre information,
appelée sortie (eh non, pas dessert). Il peut y avoir plusieurs entrées, mais seulement
une seule sortie. Toutes ces valeurs sont binaires, égales à 0 ou 1.
Chaque "synapse" du neurone formel possède un poids, c'est-à-dire une importance plus ou moins élevée par rapport aux autres. Une
information passant par une synapse au poids élevé sera donc plus importance qu'une provenant d'une synapse au poids faible.
De plus, une information égale à -1 est toujours soumise au neurone, avec un poids particulier dont nous allons
reparler plus loin.
Notons :
- k le nombre d'entrées.
- xi les entrées, avec i variant entre 1 et k (x1 sera donc la première information, x2 la deuxième, et xk la dernière).
- De la même façon, wi les poids synaptiques correspondants aux entrées (w1 sera le poids de x1 et wk celui de xk).
- l'information x0 valant -1, dont le poids est w0
Une fois "dans" le neurone formel, les informations vont donc être traitées (non, il n'est pas question
d'insultes).
Tout d'abord, le neurone va effectuer la somme pondérée des entrées, notée in : il va additionner les produits
"entrée-poids" :
in = x0 x w0 + x1 x w1 + ... + xk x wk
Ou plus simplement :
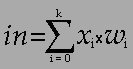
Enfin, cette somme pondérée est elle aussi traitée (toujours pas d'insultes) par le neurone, qui possède
une fonction appelée fonction d'activation. Il peut y en avoir différentes, mais les plus utilisées sont les
suivantes, toutes deux définies sur R.
Fonction de Heaviside :
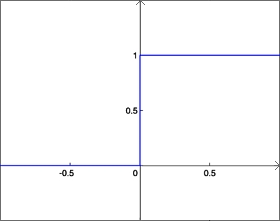
f(x) = 0 si x < 0, 1 sinon.
Fonction sigmoïde :
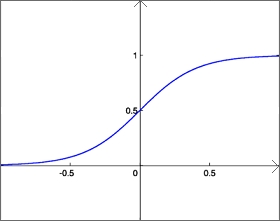
f(x) = 1 / ( 1 + e-x )
Selon la fonction, le poids w0, appelé seuil, est différent :
il est de 1 pour la fonction de heaviside, et de 0.5 pour la fonction sigmoïde.
Le retour de la fonction d'activation est comparé à ce seuil : s'il est inférieur, le neurone renvoie 0 ; s'il est supérieur, il
renvoie 1.
Bilan :
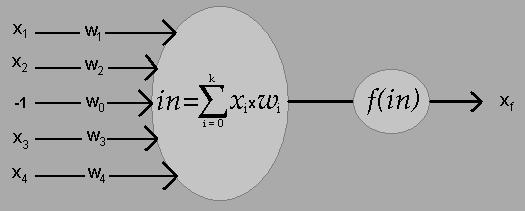
Fonctionnement d'un neurone formel seul
- Entracte : l'union fait la force -
Nous venons de voir comment fonctionne un neurone seul. Un neurone comme celui-ci peut déjà reproduire quelques fonctions logiques,
telles que la fonction OU et la fonction ET. En tracant les graphes de ces deux fonctions, que les points rouges (correspondant à la
valeur 0) et les points bleus (valeur 1) peuvent être séparés par une droite.
| Fonction OU | Fonction ET | ||||
| Entrées | Sortie | Entrées | Sortie | ||
| 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 1 | 1 | 0 | 0 |
| 0 | 1 | 1 | 0 | 1 | 0 |
| 1 | 1 | 1 | 1 | 1 | 1 |
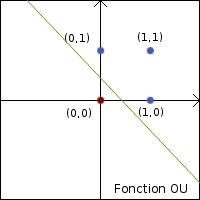
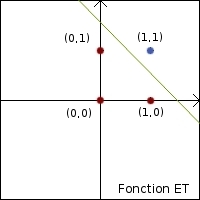
C'est là qu'apparaissent les limites du neurone seul : il ne peut reproduire les fonctions linéairement séparables, telles que la
fonction XOR.
| Fonction XOR | ||
| Entrées | Sortie | |
| 0 | 0 | 0 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 1 | 0 |
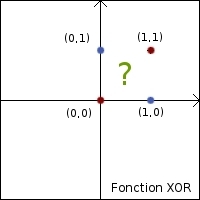
C'est ici qu'interviennent les réseaux de neurones formels. En effet, il est possible de connecter les entrées d'un neurone aux
sorties d'autres neurones, eux-mêmes connectés à d'autres neurones qui sont eux aussi reliés à des neurones
(ça fait tout un tas de neurones, ça).
Un réseau est organisé en couches : il peut être constitué d'une unique couche, et est alors appelé perceptron.
Chaque neurone de la couche reçoit toutes les informations entrées et renvoie son résultat vers un unique neurone de sortie.
Ce qu'il renvoit est la sortie finale du réseau.
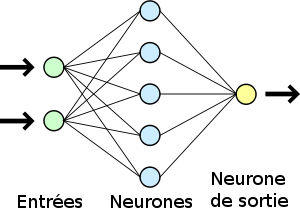
Perceptron (source)
Il peut également être multi-couches. Dans ce cas, les neurones de la première couche reçoivent toutes les informations entrées, ceux
de la deuxième reçoivent toutes les sorties des neurones de la première couche, et ainsi de suite jusqu'au neurone de sortie qui reçoit
celles de la dernière couche.

Réseau multicouche
De tels réseaux sont capables de séparer les 0 des 1 sans utiliser de droite : ils peuvent donc reproduire la fonction XOR et d'autres bien plus complexes (petit neurone seul, tu ne fais pas le poids).
II - L'apprentissage contre-attaque
Nous vous voyons d'ici hausser le sourcil en lisant le titre : mais comment un tel neurone peut-il apprendre quelque chose ?
Plusieurs algorithmes ont été mis au point pour cela, mais reposant tous sur la même chose : un neurone formel va apprendre
en modifiant les poids de ses connexions synaptiques. Ainsi, pour "entrainer" un neurone ou réseau de neurones,
il faut lui fournir des exemples (il faut tout lui donner, à ce fainéant là), c'est à dire :
- les informations d'entrées,
- la sortie attendue,
- un taux d'apprentissage alpha choisi arbitrairement.
Entrées : 0, 0 ; Sortie : 0
Entrées : 0, 1 ; Sortie : 1
Entrées : 1, 0 ; Sortie : 1
Entrées : 1, 1 ; Sortie : 1
alpha = 1
Ainsi, le neurone ou réseau pourra comparer sa sortie avec celle attendue et modifier ses poids synaptiques en conséquence.
Les deux algorithmes majoritairement utilisés pour des réseaux monocouches sont ceux de descente du gradient et celui de Widrow-Hoff, le second étant une version simplifiée du premier (simplifié n'étant pas synonyme de simple, nous le rappelons).
Algorithme de Widrow-Hoff
Cet algorithme modifie les poids synaptiques après chaque exemple, contrairement à l'algorithme de descente du gradient qui lui les modifie après le traitement de tous les exemples. Celui de Widrow-Hoff est donc plus efficace mais également plus simple à appliquer.
Les poids sont modifiés de la façon suivantee :
wi2 = wi + alpha * (Sortie attendue - Sortie du neurone) * xi
où wi est l'ancien poids, wi2 le nouveau poids et xi l'information correspondante.